
Chapter 4 - Now walk WITH me
When your table needs a table.

Big toys for big boys

Now that that we are done with the macaroni and glue, let’s move on to the big boy toys by learning on Dune V2.
The other tables will likely be deprecated in time as Dune moves into Apache Spark and Spark SQL, so best we keep up with the changes from now on.
In chapter 1 through 3, I deliberately pointed all of our queries to the Ethereum data sets, for reasons which will likely be equally oblivious and unimportant to you.
But if like my son, you really want to know what the wall tastes like, I will not prevent you from licking that thing dry.
What’s Dune new query engine all about?
Else let’s try to get to know what’s inside with simple terms.
Dune V2 datasets

In the earlier version of Dune, the query machine was not very efficient in getting data from datasets/spreadsheets, and could not do queries from multiple blockchains at a time.
This created 2 problems:
The query machine often died when hildobby woke up and started smashing that ‘Run’ button, and
We could not merge or compare data from 3 different blockchains like Ethereum and Solana.
This is why Dune created the V2 Engine and datasets, so let’s have a peek at what’s inside.
Raw

Raw data tables is the data as you get it from the blockchains, I will get to them much later in the substack.
Working with raw data tables is the metaphorical equivalent of working with flour to make pasta.
It’s not the time for that yet.
Decoded Projects
Decoded projects are specialised datasets that are project based, and are created by only gathering decoded data that transitions through project specific smart contracts.
Working with decoded project tables is the metaphorical equivalent of buying dried pasta from the supermarket to make dinner.
We will get there soon enough.
Abstractions

Abstractions are the ecosystem general data sets that have been created to facilitate generalist queries.
Working with abstractions are there metaphorical equivalent of buying Chinese takeouts and emptying the food on a plate.
This is where we will be starting.
Third Party
Let’s talk about that in a few months time young padawan.
What’s WITH
We started in Chapter 1 and Chapter 2 with those 3 line generic queries:
SELECT *
FROM some.table
WHERE something = 'value'
AND something > 'value'But by now you must have realised how constrained working with just that can be, and deep inside you feel that things can’t be that plain, and you are right.
The WITH function is the next function that we will be looking at.
To come up with a simple explanation, WITH is basically an intermediary table that we use to process data.

A simple query
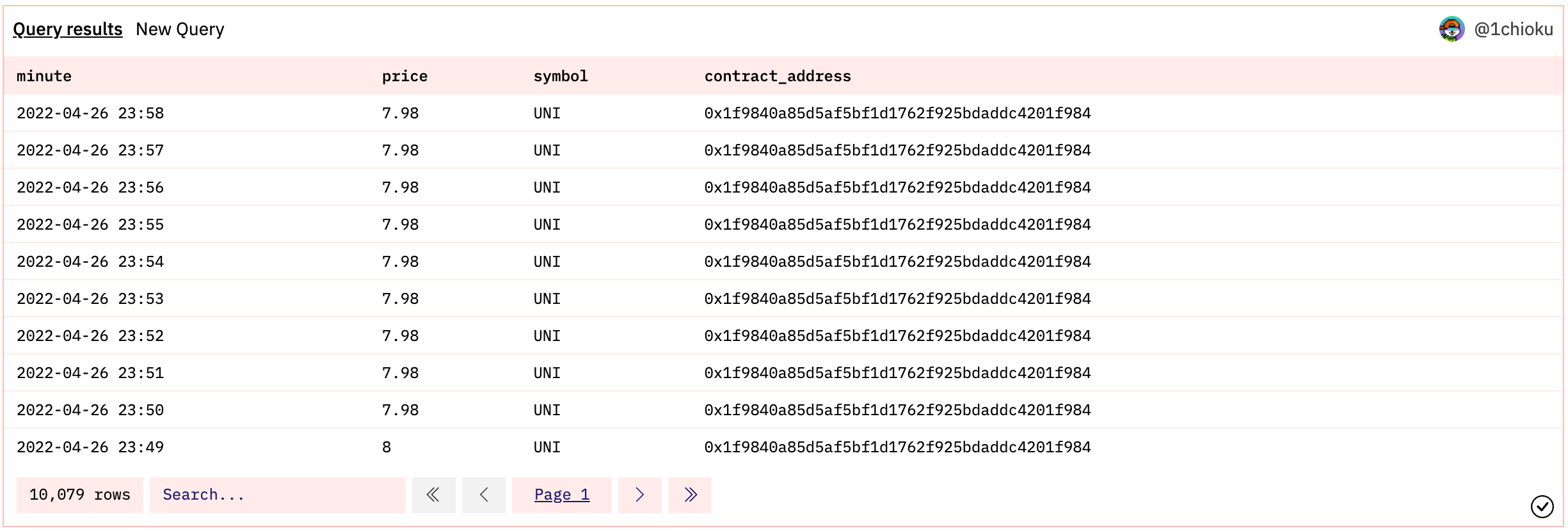
To start with, let’s use the prices.usd data table from Dune V2, and run a simple query to get UNI token prices between '2022-04-19 23:59' and '2022-04-26 23:59'.
SELECT
minute,
price,
symbol,
contract_address
FROM prices.usd
WHERE blockchain = 'ethereum'
AND symbol = 'UNI'
AND minute > '2022-04-19 23:59'
AND minute < '2022-04-26 23:59'
ORDER BY minute DESCFirst of all if you noticed, we have to add an additional filter for ethereum as in Dune V2 all the different blockchains are now in the same database, yay!
And this is the result we get when the ‘Run’ button is hit:
A more complex query
Now let’s say we want to the average price of UNI during that period that we queried.
Hmm…
So first we wrap our first results in a temporary table, which we will perform a function on to get the average price of UNI.
WITH temp AS
(
SELECT
minute,
price,
symbol,
contract_address
FROM prices.usd
WHERE blockchain = 'ethereum'
AND symbol = 'UNI'
AND minute > '2022-04-19 23:59'
AND minute < '2022-04-26 23:59'
ORDER BY "minute" DESC
)
SELECT
AVG(price)
FROM temp
A more experienced data analyst would easily be able to get the above without using the WITH function, but as a start, I highly recommend chopping up processes step by step to get your brain to adapt to programming logic.
More with WITH
The nice thing with WITH is that you can use it to add multiple temporary tables while processing up information, until you reach the point where you are fully satisfied with the data you need, e.g:
I want all the UNI token prices between '2022-04-19 23:59' and '2022-04-26 23:59';
I now want to see only those which are more than $8.00; and
I want to get the average of of all those values for the entries that are more than $8.00
WITH temp AS
(
SELECT
minute,
price,
symbol,
contract_address
FROM prices.usd
WHERE blockchain = 'ethereum'
AND symbol = 'UNI'
AND minute > '2022-04-19 23:59'
AND minute < '2022-04-26 23:59'
ORDER BY minute DESC
) ,more_than_8 AS
(
SELECT
price
FROM temp
WHERE price >= 8.00
)SELECT
AVG(price)
FROM more_than_8By segmenting our thought process and our code, we can achieve our desired results faster.
The above is pretty really awful in terms of optimisation, but hey, right now it’s about learning, we’ll touch optimisation when we cross the bridge.
Takeouts
We are now acquainted with Dune V2 and know a bit more about Dune data tables, and where to find basic data sets to play with.
WITHis a wonderful tool to use to breaking down thought processes and the code simultaneously.
Time to smash tables together!